Web Scraping in Rust With Scraper and Selenium

Rust excels in multiple areas — particularly in its performance and concurrency capabilities. These strengths make it an increasingly popular choice for web scraping.
In this tutorial, we'll explore how to scrape web content with Rust using various methods, including the Reqwest and Scraper libraries, and how to work with Selenium WebDrivers in Rust.
We’ll learn interactively by building an application that scrapes recent data from a news website, mimics a Google search, and also scrapes the most recent questions posted on StackOverflow.
Prerequisites
Familiarity with the Rust programming language
Rust and Cargo (version >1.75) set up on your system
The Chrome WebDriver from the official ChromeDriver download page
What is web scraping?
Web scraping is a technique used for programmatically collecting information from websites. At its core, web scraping requires a thorough understanding of the markup structure of the web resource in question. This knowledge tells us where and how the data we need is organized within the webpage.
For instance, if our objective is to scrape the titles and descriptions that appear when we search for "rust" on Google, our first step is to perform this search manually. Then, we carefully inspect the markup of the search results page to locate the specific HTML elements that contain the titles and meta descriptions.
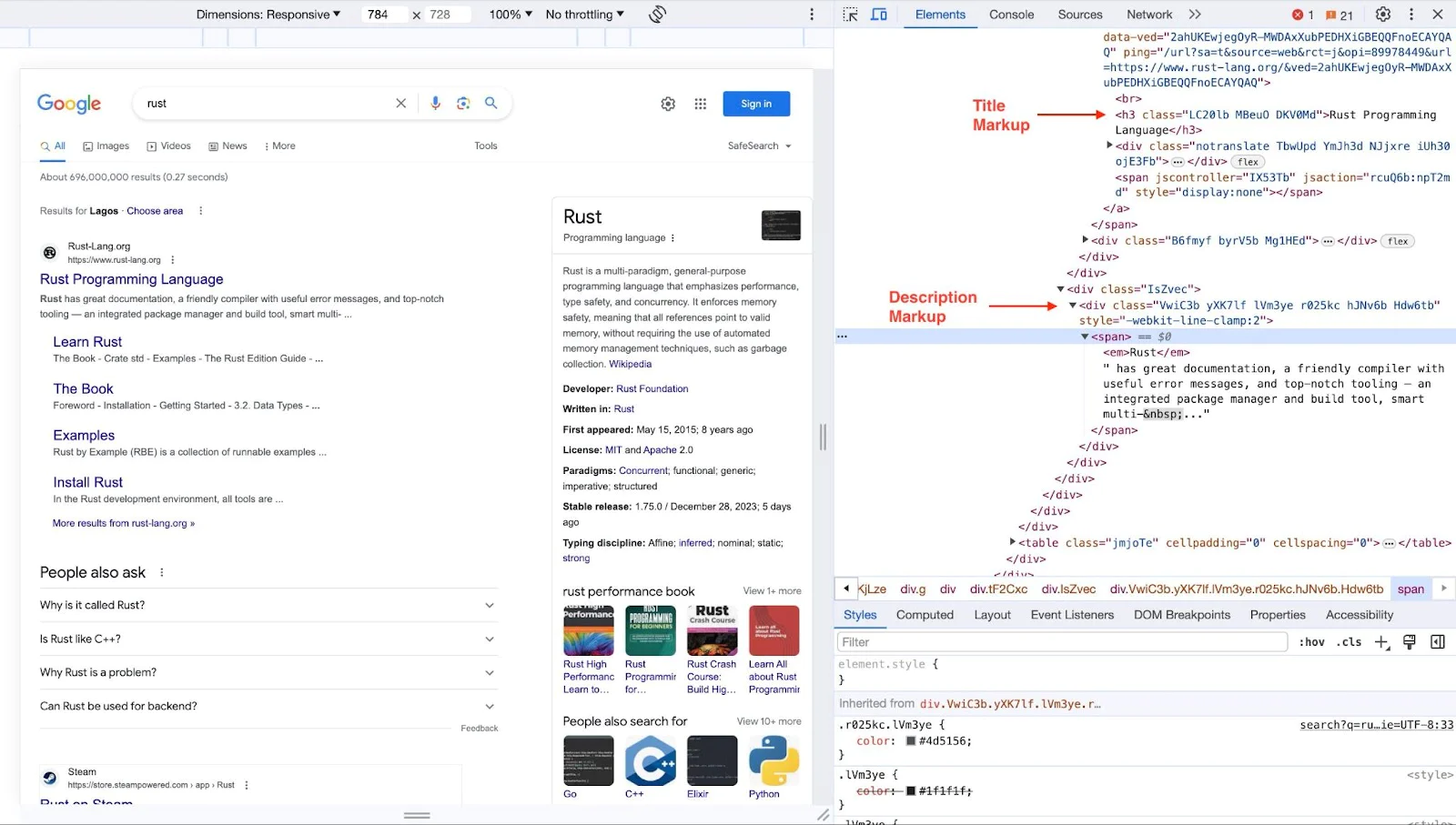
Once we've identified the necessary HTML elements and their structure, as in the screenshot above, we can write the script to navigate to the webpage programmatically, parse the HTML content, and extract the information we've identified as our target.
Web scraping can range from simple tasks, like extracting text from a webpage to more complex scenarios that involve navigating through multiple pages, handling login forms, or even dealing with JavaScript-rendered content.
Web scraping vs. data fetching
While often confused, web scraping and data fetching are distinct processes. Data fetching involves sending requests to HTTP endpoints, typically APIs (REST/GraphQL), where the data is directly accessible and structured for easy integration.
In contrast, web scraping starts with fetching the content of a web page using a library and then parsing the page's markup to extract the needed data. This process might involve using a markup parsing library to decipher HTML or XML structures. Alternatively, tools like headless browsers (e.g., Selenium) can automate interactions with more complex web pages, such as those requiring navigation or dealing with dynamically loaded content.
Scraping web content using Rust, Reqwest, and Scraper
Reqwest is an HTTP client library in Rust's ecosystem, well-known for its comprehensive data fetching capabilities. It simplifies sending HTTP requests and managing responses, making it suitable for web scraping tasks.
Conversely, Scraper is used for parsing HTML content. It navigates through markup and lets you extract specific data points from a web page's structure.
Leveraging these tools, our web scraping workflow in Rust will involve:
Utilizing Reqwest to fetch web page content
Using Scraper to parse the fetched content and extract the necessary information
Let’s start by creating a new Rust application and moving into the new project directory with the following commands:
cargo new rust-scrape
cd rust-scrape
Running this command initiates a new Rust project, generating a cargo.toml file for dependency management and a src/main.rs file containing a basic "Hello, World!" program.
Next, let’s install the Reqwest and Scraper libraries; additionally, since our application will be asynchronous, the Tokio library is required to create an async runtime. Install these dependencies using:
cargo add reqwest scraper tokio
Then, update the dependencies section in Cargo.toml to match the following:
[dependencies]
reqwest = "0.11.23"
scraper = "0.18.1"
tokio = { version = "1.35.1", features = ["rt-multi-thread", "macros"] }
With these setups in place, we're good to go!
Extracting tech news from OSNews
To demonstrate web scraping with Rust, let's extract the top five most recent articles posted on OSnews.com.
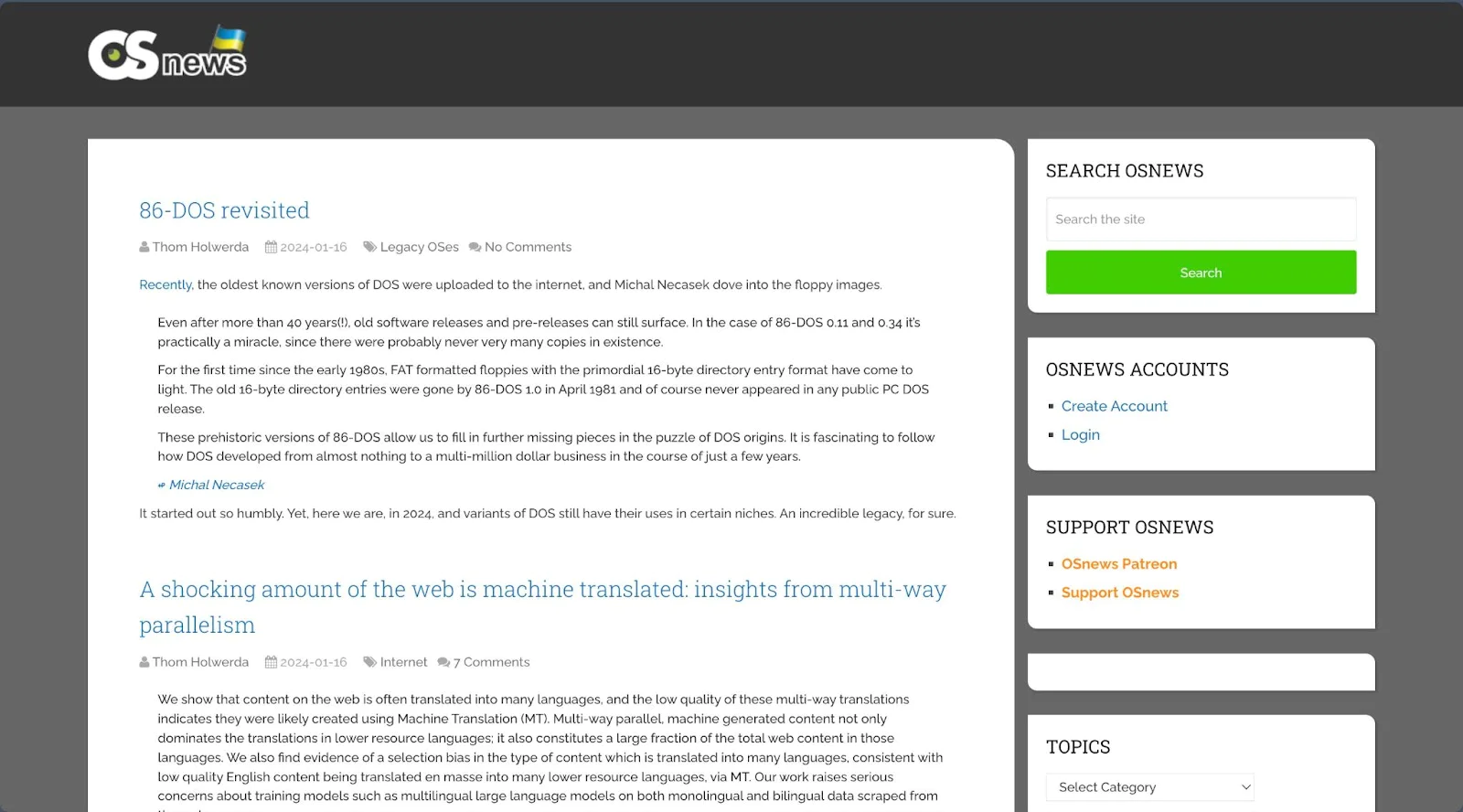
Upon inspecting the OSNews page's markup, we find that our target data is contained within the div#content_box. Inside this div, each article is wrapped in a <article> tag with the class latestPost excerpt. The article's title is located within a <h1> tag with the class title front-view-title, wrapped in a <a> tag that also contains the article's URL. The author's name is found within a span with the class theauthor, specifically in a <a> tag inside this span. The date posted is in a span with the class thetime.
With this understanding of the page structure, we can tailor our scraping script to extract these specific details. Open your src/main.rs file and insert the following Rust code:
use reqwest;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let url = "https://www.osnews.com";
let resp = reqwest::get(url).await?.text().await?;
let fragment = Html::parse_fragment(&resp);
let article_selector = Selector::parse("div#content_box article").unwrap();
let title_selector = Selector::parse("h1.title a").unwrap();
let author_selector = Selector::parse("span.theauthor a").unwrap();
let date_selector = Selector::parse("span.thetime").unwrap();
for (i, article) in fragment.select(&article_selector).enumerate() {
if i >= 5 {
break;
}
let title = article.select(&title_selector).next().unwrap().inner_html();
let author = article
.select(&author_selector)
.next()
.unwrap()
.inner_html();
let date = article
.select(&date_selector)
.next()
.unwrap()
.text()
.collect::<Vec<_>>()
.join("");
let url = article
.select(&title_selector)
.next()
.unwrap()
.value()
.attr("href")
.unwrap();
println!("Article Title: {}", title);
println!("Posted by: {}", author);
println!("Posted on: {}", date);
println!("Read more: {}", url);
println!("_____");
}
Ok(())
}
The code above sends a GET request to the OSNews homepage using the Reqwest library. After receiving the response, we use the Scraper library's Html::parse_fragment() method to parse the HTML content. We define selectors for extracting article titles, author names, dates, and URLs using Selector::parse().
The script iterates over these elements within the div#content_box, specifically targeting the articles. For each article, it extracts and prints the title, author, date, and URL. We also implemented a counter to limit the extraction to the top five latest articles, ensuring we only process the most recent content.
Start the application by running the command below.
cargo run
You should see the extracted data displayed in your console, similar to the image below.
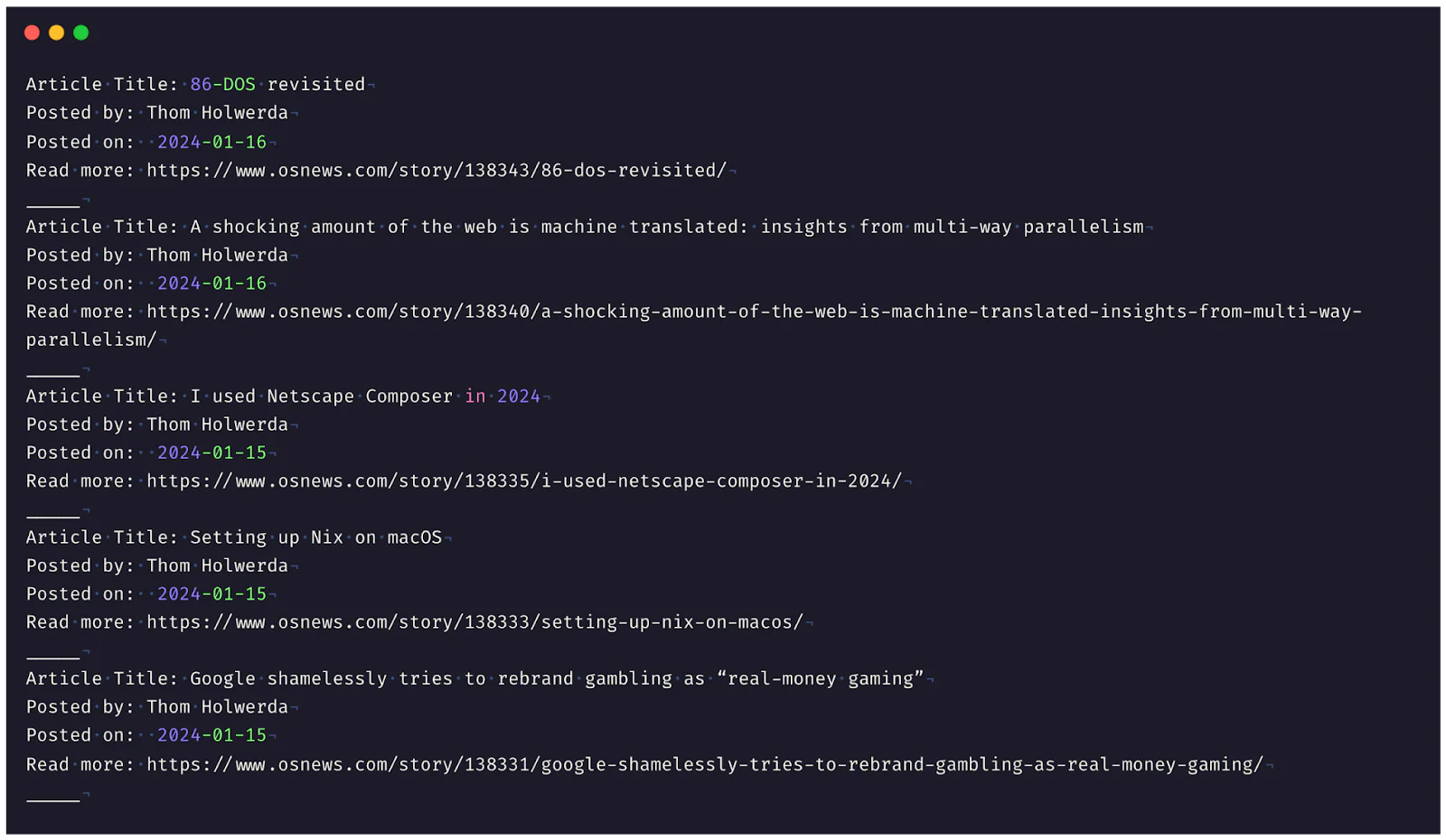
For a detailed exploration of the markup parsing methods provided by the Scraper library, visit their official documentation.
Limitations of Reqwest and Scraper for Web Scraping
While the Reqwest and Scraper libraries are effective for standard web scraping tasks, they encounter limitations with websites where content is dynamically loaded after the initial page load. In such cases, these tools can only capture the content on the first page load, missing any subsequently loaded data.
Additionally, there are scenarios where accessing the necessary data requires completing an authentication process. Reqwest and Scraper alone cannot handle such situations. In these instances, headless browser solutions like Selenium are more suitable.
Web scraping with Rust, Selenium WebDriver, and Thirtyfour
Selenium WebDriver is a popular tool for web testing and automation. It allows you to operate a fully automated browser and replicate user interactions with web pages. This capability is useful for scraping dynamic content, where data is loaded in response to user actions or asynchronously after the initial page load.
To utilize Selenium WebDrivers in Rust, we first need to install a compatible web driver. In this example, we're using the Chrome browser. Download a preferred version from the official ChromeDriver download page. Next, run the executable web driver file, and you should see a confirmation that it has started on a new port.
A compatible framework is also required to integrate Selenium WebDriver with a programming language. For Rust, this framework is Thirtyfour.
Add the Thirtyfour crate to your Rust project with the command below:
cargo add thirtyfour
With the web driver and Thirtyfour installed, you're now ready to automate browser processes in Rust.
Mimic Google search
Let's begin with a simple task: visiting google.com, searching for the keyword "rust", and scraping its contents. Open your src/main.rs file and replace its contents with the following code:
use thirtyfour::prelude::*;
use thirtyfour::Key;
use tokio;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
let caps = DesiredCapabilities::chrome();
let driver = WebDriver::new("http://localhost:9515", caps).await?;
// Navigate to Google.
driver.goto("https://www.google.com").await?;
let search_box = driver.find(By::Name("q")).await?;
search_box.send_keys("rust").await?;
search_box.send_keys(Key::Enter.to_string()).await?;
tokio::time::sleep(std::time::Duration::from_secs(5)).await;
let page_source = driver.source().await?;
println!("{}", page_source);
driver.quit().await?;
Ok(())
}
In the code, we use the Thirtyfour crate for Rust to automate a web browser. We start by creating browser capabilities with DesiredCapabilities::chrome(), which can be adapted for other browsers such as Edge using DesiredCapabilities::edge(). We then initiate a WebDriver to interact with a browser instance listening on http://localhost:9515.
The script navigates to Google's homepage, searches for the input box (identified by name="q") and enters the keyword "rust." It simulates an Enter key press to execute the search and waits briefly for the results page to load.
After displaying the search results, the script prints the page's HTML source to the console. Finally, it closes the browser window and ends the WebDriver session.
Start this program by running the following command:
cargo run
You should see a browser window open automatically, mimic the search as instructed, and print the result to the console.
However, in practice, we do not want to see the browser open and perform all the automated activities; we simply want to see the result. To accomplish this, add the "headless" parameter to launch our browser in headless mode and optionally deactivate the GPU to optimize performance, as demonstrated below.
. . .
async fn main() -> WebDriverResult<()> {
let mut caps = DesiredCapabilities::chrome();
caps.add_chrome_arg("headless")?;
caps.add_chrome_arg("disable-gpu")?;
let driver = WebDriver::new("http://localhost:9515", caps).await?;
. . .
With this argument added, the browser window won’t be visible when performing the predefined instructions.
Extract questions from StackOverflow using WebDriver
Let’s try out another example and extract the top five questions from Stack Overflow's Newest Questions page. Our focus is on capturing each question's title, excerpt, author, and complete URL. Upon inspecting the page, we find that the necessary data is contained within a div#questions tag, and each question is wrapped around another div with class s-post-summary, as shown below.
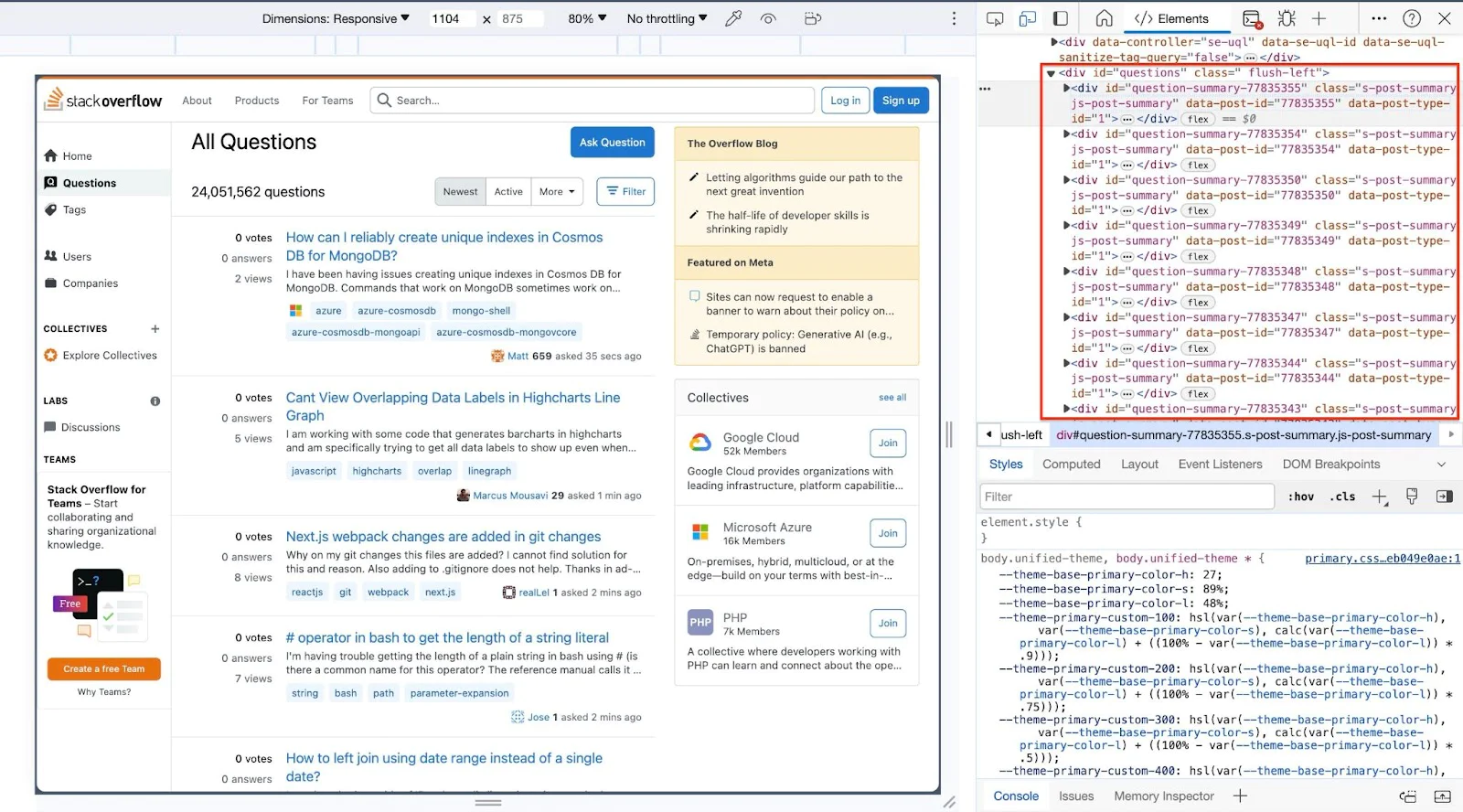
To implement this, update your src/main.rs file with the following code:
use thirtyfour::prelude::*;
use tokio;
#[tokio::main]
async fn main() -> WebDriverResult<()> {
// Set up Chrome WebDriver
let mut caps = DesiredCapabilities::chrome();
caps.add_chrome_arg("headless")?;
let driver = WebDriver::new("http://localhost:9515", caps).await?;
// Navigate to Stack Overflow's questions page
driver.goto("https://stackoverflow.com/questions").await?;
// Wait for the page to load
tokio::time::sleep(std::time::Duration::from_secs(5)).await;
// Locate the questions container
let questions = driver
.find_all(By::Css("div#questions .s-post-summary"))
.await?;
for question in questions.iter().take(5) {
// Extract question details
let title_element = question.find(By::Css("h3 .s-link")).await?;
let title = title_element.text().await?;
let url_suffix = title_element.attr("href").await?.unwrap_or_default();
let url = format!("https://stackoverflow.com{}", url_suffix);
let excerpt = question
.find(By::Css(".s-post-summary--content-excerpt"))
.await?
.text()
.await?;
let author = question
.find(By::Css(".s-user-card--link a"))
.await?
.text()
.await?;
println!("Question: {}", title);
println!("Excerpt: {}", excerpt);
println!("Posted by: {}", author);
println!("Read more: {}", url);
println!("_____");
}
driver.quit().await?;
Ok(())
}
In the code above, we use Selenium WebDriver in headless mode to navigate to Stack Overflow's questions page. After waiting for the page's content to load, we use CSS selectors to extract the first five questions' titles, excerpts, authors, and URLs. Each question's details are then printed, combining the extracted URL with 'https://stackoverflow.com' to form complete links.
To run this script and see the output, use the command:
cargo run
Running this script will display the top five most recent questions from StackOverflow in your console, similar to the output below.
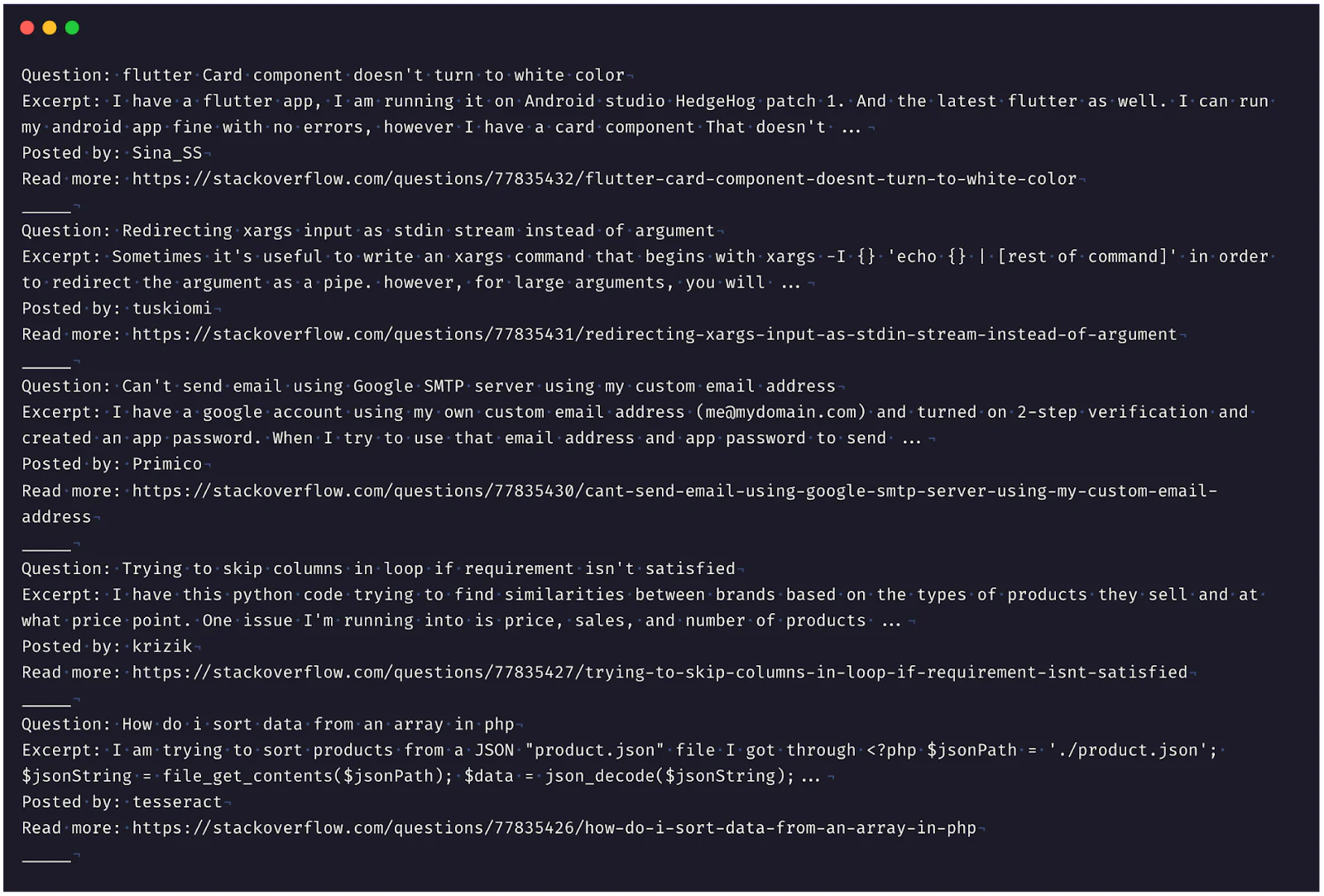
It's worth mentioning that the Selenium WebDriver's capabilities go well beyond what we've seen in this example. Selenium can automate almost any web browser interaction, including complex tasks such as navigating web pages, filling out forms, mimicking mouse movements, managing cookies, etc. Learn more about Selenium and thirtyfour.
Conclusion
Throughout this article, we've explored different web scraping methods with rust. We went from using the basic HTTP client library, Reqwest, and Scraper to advanced automated browser processes using the Selenium web driver.
For more hands-on experience, you can find the complete code used in this article on GitHub.



